在虚拟现实文本输入任务中整合基于大模型的文本预测
Virtual Reality, Text Input, Text Prediction, Large Language Modeling
项目简介
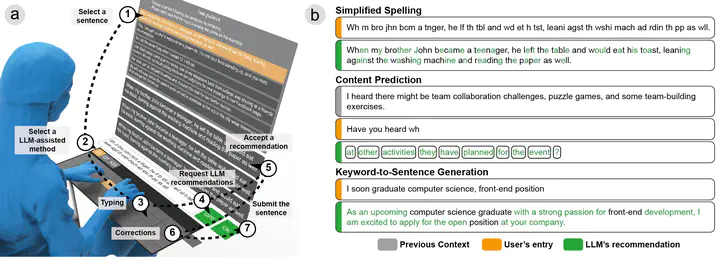
在虚拟现实中的文本输入常常面临效率和任务负荷的挑战。先前的研究探索了各种解决方案,包括专门的键盘布局、追踪的物理设备和无需手部操作的交互方式。然而,这些努力往往未能复制现实世界文本输入的效率,或引入了额外的空间和设备限制。一种可行的策略是寻求某种辅助性的文本输入方式,通过减少用户在文本输入过程中的实际击键次数来提升用户的文本输入效率和体验。本研究利用大型语言模型(LLMs)在上下文感知和文本预测方面的广泛能力,通过减少用户的手动击键来提高文本输入效率。根据英文文本自有的上下文依赖、语法关联等特性,本研究介绍了三种 LLM 辅助的文本输入方法:简化拼写、内容预测和关键词到句子生成。这三种方法分别与英文文本在单词、语法结构和句子层面的上下文可预测性相一致,且契合文本输入过程中的语言心智。我们在基于 Oculus 的 VR 原型上进行了用户实验以测试方案的有效性,实验场景涵盖了包括文本转录、对话和写作的多种文本输入任务。根据实验结果,三种辅助输入方法分别展示了 17.1%、43%和 42.9%的手动击键减少,转化为 16.6%、56.9%和 64.7%的效率提升。与手动打字相比,这些方法并没有增加手动更正的次数,同时显著减少了身体、心理和时间负荷,并提高了总体可用性。长期观察进一步揭示了用户使用这些 LLM 辅助方法的策略,表明用户对这些方法的熟练程度可以加强它们对文本输入效率的积极影响。